
As the SEMIA project reaches its final stage, we are releasing a few more posts in which we report on what we did, and learnt, over the course of the past two years.
In the first two items to appear, members of the University of Amsterdam team present some reflections on what developments in the field of computer vision can do for access to moving image collections. In a third one, the Amsterdam University of Applied Sciences team will discuss their experience of building an interface on top of the functionality for image analysis that our computer scientist developed. And in the final one, we shall introduce four SEMIA-commissioned projects in which visual and sound artists use the data we generated in the feature analysis process, to devise (much more experimental) alternatives for engaging audiences with the archival collections we sampled for our purpose.
In this second item, we talk about the role and place of classification in computer vision methods, and specifically, about how discriminative models figure into the history of the discipline, leaving a distinctive mark on how it is practiced today. We discuss the binary logic that informs such models, and explain how in the SEMIA context, it constituted a problem we had to overcome, as we sought to develop a user-centred form of collection browsing.
~
In our previous post, we touched upon some of the principles we adhered to in designing an approach to feature extraction that suits to our goal of enabling a more or less ‘explorative’ form of image browsing. In the present one, we take a step back, and reflect on the role of classification in the context of computer vision research and its applications. The common-sense meaning of the term ‘classification’ – dividing into groups or categories things with similar characteristics – is also relevant to the work we do in SEMIA. Principles and practices of classification are key to the analysis and operationalization of large numbers of data, and also feed into much work in artificial intelligence (AI), including computer vision. In this post, we work towards explaining how recent developments in this field, and specifically tendencies towards discriminative classification, impacted on our work in the SEMIA project.
Computer vision, a specialist area within AI, is concerned with how computers can be taught to ‘see’, or ‘understand’, (digital) images or image sequences. Which of those verbs one prefers to use, depends on one’s perspective: on whether one conceives of the human capacity computers are taught to imitate or emulate as a function of perception (seeing), or rather cognition (understanding). In the 1970s, as the discipline of computer vision was taking shape, practitioners conceptualised it as “the visual perception component of an ambitious agenda to mimic human intelligence and to endow robots with intelligent behaviour” (Szeliski 2009, 11). Richard Szeliski, a long-time contributor to the field, recalls that at the time, it was assumed that “solving the ‘visual input’ problem would be an easy step to solving more difficult problems such as higher-level reasoning and planning” (Ibid.). In the intervening decades, this has proven to be an unwarranted expectation. Today, imitating the human capacity of recognising images is actually seen as one of the more challenging tasks informatics has taken on. This is both because of the complexity of the problems that require solving in order to make it possible (as vision is considered an ‘inverse problem’, it involves the recovery of many unknowns) but also because it relies on a wide range of mathematics disciplines (Szeliski 2009, 3, 7). However, confusion over the distinction in perspective between vision-as-perception and vision-as-cognition persists, and in the field, both frameworks continue to wield their influence, often independent of one another. (And perhaps unsurprisingly so, because in the past decades, even cognitive scientists have reached little consensus in this area; cf. Zeimbekis and Raftopoulos 2015; Pylyshyn 1999.)
Simply put, research in the field of computer vision is concerned with developing models for extracting key information, or visual ‘features’, from (still and moving) images, so that they can be cross-referenced. Extraction, in this context, involves an analysis: a transformation of images into descriptions, or so-called ‘representations’, which are used in turn to classify them – or rather, their constitutive elements. This way, practitioners reason, computers automate what humans do as they recognise elements in a picture or scene. (Interestingly, the distinction between those two, in an AI context, is generally considered non–essential, as it is ultimately always the ‘real’ world that serves as a touchstone for accurate identification. From a humanities perspective, this entails that the role of mediation is glossed over.)
The applications of computer vision research are extremely diverse. Models and methods emerging from it are used in military and security systems (e.g. for the purpose of surveillance), but also in medical software (such as, image analysis tools used for diagnostics or to support operative treatment). They are integrated into equipment for navigation (for instance, in the development of self-driving cars) and traffic control, and used in various other commercial contexts (e.g. for quality assurance and logistics in the manufacturing industries and retail, or as part of consumer products for film and video production). Within computer vision research, video retrieval, or the content-based retrieval of digital moving images, has been an active area of inquiry since the beginning of the century (with some projects, such as the well-known TRECVIC, running for almost two decades). In recent years, methods developed in this field have also been repurposed to navigate large databases of moving images; for instance, to support digital cinema scholarship (e.g. Virginia Kuhn and her team’s VAT, or Barbara Flückiger et al.’s VIAN – both efforts that SEMIA builds on) or for the development of movie recommendation systems (see e.g. Bougiatiotis and Giannakopoulos 2018). However, the latter type of applications are more marginal in both scale and societal impact, compared to the aforementioned ones.
Feature extraction, we mentioned, is a matter of describing images or image sections based on information about their potentially significant visual characteristics. This process results in representations, that are used in turn to classify them: as computer vision algorithms are executed, decision rules are applied that determine, on the basis of the extracted features, which categories the images in a database belong to. This is true for task-specific algorithms, but also for various machine-learning systems, such as neural nets. (See our previous post for an explanation of the distinction between the two.) However, in popular discourse on AI, this fact is often overlooked. As Anja Bechmann, a digital sociologist, and Geoffrey C. Bowker, an authority in the field of Science and Technology Studies (STS) observe (2019), it is often assumed that in machine-learning applications, classification does not take place, because categories are no longer constructed a priori (4). In reality, however, AI heavily relies on statistics – a science of classification. And for Bechmann and Bowker, classification is just “another word for generalization” (ibid.).
For this reason, classification raises a number of issues – at least, if we consider it from a socio-political perspective. From the point of view of computer vision, it is key that systems are designed and trained to generalise among variations, as this increases the chance of them successfully identifying the images in a database (see our previous post). In this context, then, generalisation entails (greater) potential – in the sense of (better) performance or (broader) usability. However, for social and cultural critics, any form of generalisation inevitably always results in a reduction of potential. Labelling and classifying, which are common practice in many forms of image analysis, involve the making of determinations as to what is or isn’t relevant. (This is true even in cases where abstract, lower-level features are extracted – the kind we focus on in SEMIA, as we discussed in our previous post.) And as STS scholar Adrian MacKenzie (2017) explains, any such determination always operates according to a logic of reducing, rather than opening up, a wider range of possibilities (7) – also at the very basic level of what is taken to be visually significant. In the process, choices are made between alternative options, even if the making of such choices is left to machines.
As many before us have pointed out, this has profound socio-political implications. Even machine learning systems that operate in largely unsupervised ways (that is, systems that do not depart from a ‘ground truth’, or human understanding of what their output values should be; see here for further elaboration) necessarily rely to some extent on “institutionalized or accepted knowledges”, along with their associated categories (MacKenzie 2017, 10). One reason for this is that it is humans who feed them the data they extract information from. And as Bowker and Star (1999) taught us decades ago, even the most broadly agreed-upon categories are inevitably infused with bias. Such bias may derive from the specific epistemic contexts in which those categories emerged (cf. Day 2014), but in AI systems, it is further re-enforced by the most popular applications of its methods and tools. As we explained, the results of computer vision research have been operationalised primarily for situations that involve the recognition, and identification, of semantic entities, and specifically ‘objects’ (for instance, vehicles, humans and elements of the built environment, as in traffic and transportation applications). Yet aside from the fact that as a result, the algorithms involved have a keener eye for ‘things’ than other classes (see Caesar, Uijlings and Ferrari 2018), they also normalise classification practices that are often considered problematic.
As the scholar-artist duo Kate Crawford and Trevor Paglen (2019) argue, questions around the meaning of images – a topic of debate in philosophy, art history and media theory for many decades – become all the more pressing in the context of machine learning and the categorizations it involves. One reason for this is that in AI systems, the logics behind labelling and classifying get increasingly shielded from view. In many cases, even informaticians do not understand how exactly their algorithms work, or how specific determinations have been made (e.g. Domingos 2015, xv-xvi). (Hence also the growing interest today in ‘explainable AI’, or XAI: an emerging area of machine learning that seeks to make AI algorithms more transparent, also in response to the rights of those whose lives are affected by them.) This black-boxed-ness becomes particularly problematic if the images that are subjected to automatic interpretation also feature persons. As people are labelled in the manner of objects, Crawford and Paglen vividly illustrate, one encounters assumptions about gender, race, ability and age that are not only unsubstantiated, but even hark back to such nineteenth-century pseudo-scientific practices as phrenology (likewise performed without the consent of those represented).
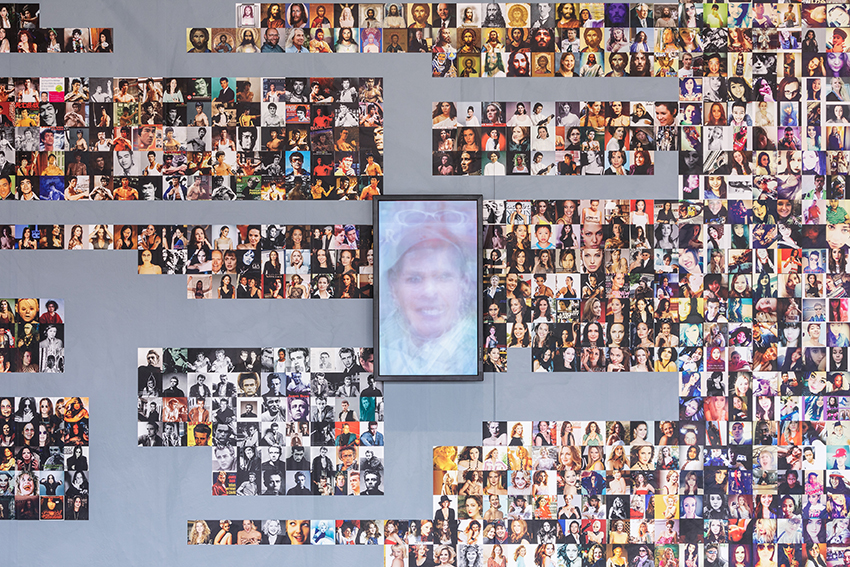
Promotional still for the exhibit Training Humans, curated by Kate Crawford and Trevor Paglen at the Fondazione Prada in Milan (Italy), which runs until 24 February 2020
As we mentioned, both computer scientists and social and cultural theorists point in this context to the composition and role of the datasets that are used for training machine-learning algorithms, and that “shape the epistemic boundaries governing how [such] systems operate” (Crawford and Paglen 2019). For instance, DeVries et al. (2019) recently discussed the selective geographical coverage of items shown in the images contained in widely accessible object-recognition training sets, arguing that they tend to be Western-centric. (The authors focus in their study on images containing household items, raising issues both with their selection, and with the objects’ relation to the home environments in which they feature.) Crawford and Paglen (2019) however argue that greater diversity in the selections made – a solution also DeVries et al. propose – does not necessarily solve the problem of embedded bias. They explain that one of the common properties of training sets’ architectures is that they consist of three layers for the labelling, and sorting into categories, of the images they contain: an overall taxonomy (“the aggregate of classes and their hierarchical nesting”), the individual classes (“the singular categories that images are organized into”) and finally, each individually labelled image. Using the example of ImageNet, one of the most often-used sets for training for object recognition (which also the network used in SEMIA relies on [1]), they demonstrate how each of those layers is “infused with politics”, due to a reliance on problematic assumptions: about the existence of specific concepts (as fixed and universal, and having internal consistency), about the relation between concepts and images or appearance and ‘essence’, and about the capability of statistics to determine (visual) ‘essence’ (Crawford and Paglen 2019).
Another issue the authors touch upon but do not elaborate, is that today’s computer vision systems, including neural nets, are built to develop models for recognising differences between a closed set of classes. The result is that they work to generate binary results: either an image positively belongs to class X, or it does not (Vailaya, Jain and Zhang 1998). Above, we explained that from a critical perspective, all algorithmic categorisation results in a reduction of possibilities – for the simple reason that the allocation of a (semantic) label always excludes the allocation of certain others. However, today’s computer vision methods confound this situation, as they typically involve a limited set of classes among which difference is established. Once again, this raises profound issues; after all, it should not be assumed that a thing, but certainly a person, either positively belongs to one category, or to another.
But in the SEMIA context, it also hampers the development of an alternative to query-based search. In explorative browsing, after all, the purpose is not to find something that meets very specific criteria. (We elaborated on this in our previous post.) Therefore, it would in fact be preferable if the results a system generates were not limited to what is identical or near-identical (as in: X either is a cat, or it is not) but also included items on the spectrum of the somewhat similar (X is like a cat). At present, images in those ‘grey areas’ simply are not being classified (cf. Valaiya, Figueiredo, Jain and Zhang 2001) and as such, the decision as to whether they might be relevant are also taken out of the user’s hands. The reason is that the algorithms used are optimized to achieve the highest possible level of certainty in a process of identification.
Some clues as to how this situation came to be can perhaps be found in the development history of computer vision. To explore this possibility, we briefly trace this history, distinguishing in the process between three (broad) developmental phases. Our purpose here is to discuss when and how choices that still determine how computer vision is practiced today, got introduced. Arguably, this can help reveal why we are currently left with assumptions and views that over time got increasingly taken-for-granted, but are certainly worth challenging – within the SEMIA context, but perhaps also beyond.
In the very early years of computer vision, in the 1960s, the ultimate objective was to build ‘vision systems’ that would allow the planning and reasoning components then prominent in AI to be used to reason about the real world. As we pointed out before, the field’s pioneers, such as Seymour Papert and his colleagues at MIT and elsewhere, were rather too optimistic about how quickly this task might be accomplished.[2] Much of this early work revolved around the idea that the world around us consists of objects, and that by identifying those objects, we can understand the world. For this reason, specific approaches focused on decomposing images into lines, and developing methods for extracting from those lines contiguous shapes (that is, shapes with common borders) that could then be matched to templates of known objects (Roberts 1963). Throughout this first phase of the field, which approximately lasted until the late 1990s, the dominant paradigm was focused on formal geometric description. Over time, approaches for describing and matching shapes became more mathematically sophisticated, but even so, they still relied on analysis methods designed by humans, as well as manually specified matching or decision rules.
The second phase we identify began in the late 1990s and early 2000s. It is marked by the emergence of feature-based approaches, which relied on mathematically complex algorithms for finding and describing local areas or points of interest in images (Mundy 2006). The algorithms used at the time were still designed by humans; however, they were quite flexible in terms of how features got extracted from realistic images, and this made it possible for systems to automatically learn the templates (or models) describing objects from sets of images. As such, they heralded a larger role for machine learning in computer vision. For the user, these developments removed the burden of having to specify decision rules; however, they also shifted this burden to finding and specifying sets of images representative of given objects. Moreover, due to the choice of learning paradigm that was made at the time – one of discriminative learning – it additionally placed a burden on the image set as such, in its entirety.
‘Discriminative’ (learning) models, as opposed to ‘generative’ models, do not centre in the analysis process on the characteristics of the objects themselves, but rather on the characteristics that make them different from other objects, within the context of the dataset provided (see e.g. Ng and Jordan 2001). In other words, the learnt characteristics of an apple, for example, will be different if the only other object represented in the dataset is an orange (in which case they can be distinguished from each other based on colour alone) than if the dataset contains a rich and varied collection of objects. After all, something red and round could be an apple, but it might as well be a traffic light. In terms of the aforementioned ‘burden’ on the dataset, this also means that while two classes may be easy enough to distinguish based on canonical examples, it becomes more difficult when alternative forms or views also come into play. For this reason, larger and more varied datasets necessitate a more detailed description of the objects in them. And, due to this interaction between algorithms’ performance and the datasets they are trained on, the field of computer vision has since also begun to work with increasingly large datasets, featuring more varied selections of classes (as also exemplified by DeVries et al. 2019).
The increase in size and diversity of datasets in turn places an enormous constraint on the representational power of the chosen features. Accurately distinguishing between very similar classes, indeed, requires a feature representation that is rich enough to make this possible. This brings us to the third, and current, phase of computer vision, inaugurated by the resurgence of representation or deep learning algorithms in the early 2010s. Rather than relying on sophisticated mathematical, but manmade, algorithms, such methods use algorithms that learn the feature representation for a given dataset in a way that optimises their performance. Learning algorithms are used in both the feature extraction component of the process (the stage when image areas are transformed into descriptions or representations) and in that of object model construction (when a mathematical model is generated to describe the featured objects). Both are fully data-driven, and because of their reliance on a discriminative learning paradigm, will focus on what makes the classes in the dataset different from each other, rather than to learn generalisable characteristics of the objects. This focus has ultimately led to better performance on a range of computer vision tasks, but at the same time, it has aggravated some of the political issues discussed above. (After all, are any categories quite as mutually exclusive as the system makes them out to be?)
The typically narrow manner in which computer vision algorithms recognise objects, along with their strong focus on semantic recognition (see our previous post), inevitably impact on their potential for reuse. This is significant also in the SEMIA context, where we seek to enable users to browse – rather than search – large moving image collections, and have therefore had to reckon with the consequences of the abovementioned developments. To conclude this post, we briefly discuss how they affected our process, and what we did to counteract the constraints they imposed.
In the computer vision field, a great deal of effort has been taken to improve search methods, with a specific focus on increasing performance in the area of retrieval. In retrieval, the goal is to return matches within a given database of (moving) images, based on a query. Typically, the performance of systems designed for this task is measured in terms of precision and recall. ‘Precision’, in this context, describes the proportion of results in the set of returned results that are deemed ‘correct’. Recall, in turn, specifies which proportion of all possible ‘correct’ results was contained in the set of returned results. A key notion in measuring precision and recall, in other words, is that of ‘correctness’: for a given query, there are results that are correct and others that are not. In order to produce such judgments, computer vision algorithms rely on labelled data. Through its labelling, the data reveals what is considered correct and what isn’t, as understood by the developers of algorithms and training datasets and incorporated into their design.
In the academic, experimental setting in which computer vision algorithms are developed, the aim is to maximise performance on metrics such as precision and recall. However, regardless of how problematic this is from an epistemic perspective (correctness, in this context, being a highly relative concept) or a socio-political one (consider, once again, the bias ingrained in the abovementioned practices of labelling), one might argue also that for practical implementations that involve a good deal of user interaction, it might not even be the main priority.
In search, the emphasis is typically on precision, because in submitting a query, a user tends to prefer a situation whereby the first few results are very close matches, in the sense of ‘correctness’ as discussed above. A searcher will much more easily notice low-precision cases (those results that do not match the query) than low-recall cases, where the missing results are typically ‘unknown unknowns’ (results one did not know of beforehand, and therefore does not miss). For browsing purposes in contrast, higher recall tends to be more desirable, as it presupposes a user seeking to explore the diversity of the materials in a database. If one is shown only those items that represent slight variations of the same, narrowly defined concept, this simply isn’t possible. Developing computer vision algorithms, then, involves a trade-off between maximising precision, and maximising recall – or otherwise, finding a balanced ‘average’ between the two.
In all of these cases, however, developers are forced to rely on pre-existing definitions of concepts and their scope. Unless, of course, they choose not to go for classification into concepts at all, and rather express similarity as a ‘continuous’ concept (instead of one of ‘match’ or ‘mismatch’). Arguably, this is exactly what we did in the SEMIA case.
We previously discussed how we decided in the project to work outside the existing framework for feature extraction, which entailed that instead of designing (or having the system automatically learn) decision rules for which classes items belong to, we relied on the ‘raw’ (that is, lower level, syntactic) features. In practice, we used those features to map each item to a point in a contiguous ‘feature space’ (see here for an explanation of this notion that extends beyond the field of computer vision). So, while we still relied in the extraction process on algorithms trained for object recognition, we no longer used them to this end. By thus foregoing classification using (narrow) concepts, and describing visual content based on features instead of categories, we relied on an expression of similarity as a continuous concept, rather than a binary one. For the user of our interface, this will entail that browsing or exploring becomes a form of ‘walking through’ a feature space, whereby each next step is determined by the visual similarity between items rather than their semantic labelling.
Of course, this approach still builds on one that is commonly used for retrieval purposes; however, we do not evaluate it using performance measures relying on labels, that require a definition of what either is or isn’t ‘correct’. Instead, we focus on the user and their experience, but also their ability to explore a database or collection, or get inspired by the material they encounter. In the following posts in this series, we explore further how we have worked with the features thus extracted to design an interface for making the images in our repository accessible to users.
– Eef Masson and Nanne van Noord
Notes
[1] The results we will be sharing via our prototype interface (to be discussed in an upcoming post on this blog) are the outcome of an analysis based on (many) more than 1,000 classes. See Mettes, Koelma and Snoek 2016 for more information.
[2] There is a famous story, which seems to have some basis in reality, about a 1966 project in which students were asked to build a significant part of such a vision system in a single Summer; see Papert 1966. Yet it soon became clear that ‘solving the vision problem’ might not be quite as trivial as it appeared to be.
References
Bechmann, Anja, and Geoffrey Bowker. 2019. “Unsupervised by Any Other Name: Hidden Layers of Knowledge Production in Artificial Intelligence on Social Media.” Big Data and Society, advance online publication. 1-11. Doi: 10.1177/2053951718819569.
Bougiatiotis, Konstantinos, and Theodoros Giannakopoulos. 2018. “Enhanced Movie Content Similarity Based on Textual, Auditory and Visual Information.” Expert Systems With Applications 96: 86-102. Doi: 10.1016/j.eswa.2017.11.050.
Bowker, Geoffrey C., and Susan Leigh Star. 1999. Sorting Things Out: Classification and Its Consequences. Cambridge, MA: MIT Press.
Caesar, Holger, Jasper Uijlings, and Vittorio Ferrari. 2018. “COCO-Stuff: Thing and Stuff Classes in Context.” In 2018 IEEE conference on Computer Vision and Pattern Recognition, n.p. Computer Vision Foundation, 2018.
Crawford, Kate, and Trevor Paglen. 2019. “Excavating AI: The Policitcs of Images in Machine Learning Training Sets” (blog post). Excavating AI. 19 September.
Day, Ronald. 2014. Indexing it All: The Subject in the Age of Documentation, Information, and Data. Cambridge, MA: MIT Press.
DeVries, Terrance, Ishan Misra, Changham Wang, and Laurens van der Maaten. 2019. “Does Object Recognition Work for Everyone?” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 52-59. Available from arXiv:1906.02659.
Domingos, Pedro. 2012. “A Few Useful Things to Know about Machine Learning.” Communications of the ACM 55, no. 10: 78-87. Doi: 10.1145/2347736.2347755.
MacKenzie, Adrian. 2017. Machine Learners: Archaeology of a Data Practice. Cambridge, MA: MIT Press.
Mettes, Pascal, Dennis C. Koelma, and Cees G.M. Snoek. 2016. “The ImageNet Shuffle: Reorganized Pre-training for Video Event Detection”. In Proceedings of the 2016 ACM International Conference on Multimedia Retrieval (ICMR’16), 175-182.New York: ACM. Doi: 10.1145/2911996.2912036.
Mundy, Joseph L. 2006. “Object Recognition in the Geometric Era: A Retrospective.” In Toward Category-Level Object Recognition (volume 4170 of Lecture Notes in Computer Science), ed. by Jean Ponce, Martial Hebert, Cordelia Schmid, and Andrew Zisserman, 3-28. Berlin Heidelberg: Springer.
Ng, Andrew Y., and Michael I. Jordan. 2001. “On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes.” In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic (NIPS’01), ed. by Thomas G. Dietterich, Suzanna Becker, & Zoubin Ghahramani, 841-848. Cambridge, MA: MIT Press.
Papert, Seymour. 1966 “The Summer Vision project.” Unpublished document. Available from https://dspace.mit.edu/handle/1721.1/6125.
Pylyshyn, Zenon. 1999. “Is vision continuous with cognition? The case for cognitive impenetrability of visual perception.” Behavioral and Brain Science 22, no. 3: 341-423. See here for a reprint in pdf.
Roberts, Lawrence G. 1963. “Machine Perception of Three-Dimensional Solids.” Unpublished PHD dissertation, Massachusetts Institute of Technology, Cambridge (MA). Available from https://dspace.mit.edu/handle/1721.1/11589.
Szeliski, Richard. 2009. Computer Vision: Algorithms and Applications. London: Springer.
Vailaya, Aditya, Anil K. Jain, and Hong-Jiang Zhang. (1998). “On Image Classification: City Images vs. Landscapes.” Pattern Recognition 31, no. 12: 1921-1935. Doi: 10.1016/S0031-3203(98)00079-X.
Vailaya, Aditya, Mário A.T. Figueiredo, Anil K. Jain, and Hong-Jiang Zhang. 2001. Image Classification for Content-Based Indexing. IEEE Transactions on Image Processing 10, no. 1: 117-130. Doi: 10.1109/83.892448.
Zeimbekis, John, and Athanassios Raftopoulos, eds. 2015. The Cognitive
Penetrability of Perception: New Philosophical Perspectives.
Oxford: Oxford University Press.