As the SEMIA project has been completed, we gradually release a few more posts in which we share results and report on what we did and what we learnt during the project.
In the first two items that have appeared in this series (see here and here), members of the University of Amsterdam team reflected on what developments in the field of computer vision can do for access to moving image collections. In the upcoming posts, the Amsterdam University of Applied Sciences team will discuss their experience of building an interface on top of the functionality for image analysis that our computer scientist developed. Moreover, we share more info on the work and/or reflections resulting from four SEMIA-commissioned projects in which visual and sound artists use the data we generated in the feature analysis process, to devise more experimental alternatives for engaging audiences with the archival collections we sampled for our purpose.
In this third item, we introduce the artists we worked with in the project’s final stage and share a work that one of these collaborations resulted in – the video work Alien Visions (2020) by Pablo N. Palma and Bram Loogman.
~
In the final stage of the SEMIA project – in which we began testing and experimenting with the results we had achieved through our feature extraction work – we involved a few artists more closely. The aim of doing so was to obtain an impression of how artists might imagine browsing and working with Eye’s and the Netherlands Institute for Sound and Vision’s collection based on the data we had extracted. Through these collaborations we also hoped to discover alternatives to the interface we had devised ourselves. In total we collaborated with five artists – three individual artists and one artist duo – a couple of which had already been closely involved in the research process in the context of the workshop and symposium events we had organized in the project.
The Artists
The artists we commissioned to work with the material have backgrounds in the fine arts, film & video art and sound art. Artist Jason Hendrik Hansma (see Jason Hansma’s website here) incorporates a wide variety of different media (photography, sculpture, drawing, text, glass, video, and painting) and explores – to cite Hansma’s own presentation – “notions of the in-between, the liminal, and the nearly articulate”. In relation to especially Eye’s collection, this led Hansma to search for and explore material that in various ways shows the transition of bodies or fluid states – for instance images of water, shimmering surfaces or bodies moving in water. Moreover, Hansma’s work focusses on the transitional nature of film materials in the digitization and restoration process. We also collaborated with media scholar and artist Szilvia Ruszev (for more visit Silvia’s website here). Currently pursuing a PhD in Media Arts and Practice at UCLA, Ruszev’s work explores – among other topics – an interest in rhythm and montage in relation to classic film theory and recent film data visualization tools and strategies. Sound artist and programmer Adam Juraszek works with various sound sources – among other radio and broadcast sound snippets – that he processes in the SuperCollider software (listen to his release Rendered Environments (2016) on Søvn Records here). For SEMIA, Juraszek has been exploring strategies for creating sonifications of the data we extracted from the Open Images collection. Finally, we have been working with the film- and videomaking artist duo Pablo Nunez Palma and Bram Loogman. Among other practices, Palma and Loogman explore a combination of found footage and structural filmmaking and algorithmic, generative approaches to editing archival footage. In doing so they explore the implications of contemporary digital database environments. They have previously worked with Eye Filmmuseum in their successful Jan Bot project (2017) which remixed footage from Eye’s collection based on trending news topics data (check out Jan Bot here). In this post we present Palma and Loogman’s new work Alien Visions (2020) commissioned by the SEMIA project.
Alien Visions (2020)
In their new work Alien Visions, Palma and Loogman use SEMIA feature data as a basis for browsing and selecting newsreel footage. Focussing in particular on feature data relating to shape, they critically explore the data and the moving images retrieved with it in a work that combines found footage filmmaking with a sci-fi thought experiment. In his message to the SEMIA research team, Pablo N. Palma gave the following description of the work’s underlying process and premise:
“We worked with Polygoon material [newsreel footage made available by Netherlands Institute for Sound and Vision via the Open Images platform], most of which were black and white. This meant that the only effective sorting criteria, colour, wasn’t usable. So we decided to use shape recognition. The results we got did not give many hints about a visual pattern our human minds could decipher, so we decided to make a film about that, about the mysteries of sense-making, about how machines are capable to create logical patterns that are impossible for humans to understand. In other words, trying to understand a machine can be literally like trying to understand an alien from a distant planet.
And then we thought: what if we were the machine and the human was the alien? That was the experiment”
As the SEMIA project reaches its final
stage, we are releasing a few more posts in which we report on what we did, and
learnt, over the course of the past two years.
In the first two items to appear,
members of the University of Amsterdam team present some reflections on what
developments in the field of computer vision can do for access to moving image
collections. In a third one, the
Amsterdam University of Applied Sciences team will discuss their experience of
building an interface on top of the functionality for image analysis
that our computer scientist developed. And in the final one, we shall introduce
four SEMIA-commissioned projects in which visual and sound artists use the data we generated in
the feature analysis process, to devise (much more experimental) alternatives
for engaging audiences with the archival collections we sampled for our
purpose.
In this second item, we talk about the role and place of classification in
computer vision methods, and specifically, about how discriminative models figure
into the history of the discipline, leaving a distinctive mark on how it is
practiced today. We discuss the binary
logic that informs such models, and explain how in the SEMIA context, it
constituted a problem we had to overcome, as we sought to develop a user-centred
form of collection browsing.
~
In our
previous post, we touched upon some of the principles we adhered to in
designing an approach to feature extraction that suits to our goal of enabling
a more or less ‘explorative’ form of image browsing. In the present one, we
take a step back, and reflect on the role of classification in the context of computer vision research
and its applications. The common-sense meaning of the term ‘classification’ – dividing
into groups or categories things with similar characteristics – is also
relevant to the work we do in SEMIA. Principles and practices of classification
are key to the analysis and operationalization of large numbers of data, and
also feed into much work in artificial intelligence (AI), including computer
vision. In this post, we work towards explaining how recent developments in this
field, and specifically tendencies towards discriminative classification,
impacted on our work in the SEMIA project.
Computer
vision, a specialist area within AI, is concerned with how computers can be
taught to ‘see’, or ‘understand’, (digital) images or image sequences. Which of
those verbs one prefers to use, depends on one’s perspective: on whether one
conceives of the human capacity computers are taught to imitate or emulate as a
function of perception (seeing), or rather cognition (understanding). In the
1970s, as the discipline of computer vision was taking shape, practitioners conceptualised
it as “the visual perception component of an ambitious agenda to mimic human
intelligence and to endow robots with intelligent behaviour” (Szeliski 2009, 11).
Richard Szeliski, a long-time contributor to the field, recalls that at the
time, it was assumed that “solving the ‘visual input’ problem would be an easy
step to solving more difficult problems such as higher-level reasoning and
planning” (Ibid.). In the intervening
decades, this has proven to be an unwarranted expectation. Today, imitating the
human capacity of recognising images is actually seen as one of the more
challenging tasks informatics has taken on. This is both because of the
complexity of the problems that require solving in order to make it possible (as
vision is considered an ‘inverse problem’, it involves the recovery of many
unknowns) but also because it relies on a wide range of mathematics disciplines
(Szeliski 2009, 3, 7). However, confusion over the distinction in perspective
between vision-as-perception and vision-as-cognition persists, and in the
field, both frameworks continue to wield their influence, often independent of one
another. (And perhaps unsurprisingly so, because in the past decades, even cognitive
scientists have reached little consensus in this area; cf. Zeimbekis and
Raftopoulos 2015; Pylyshyn 1999.)
Simply
put, research in the field of computer vision is concerned with developing models
for extracting key information, or visual ‘features’, from (still and moving) images,
so that they can be cross-referenced. Extraction, in this context, involves an
analysis: a transformation of images into descriptions, or so-called
‘representations’, which are used in turn to classify them – or rather, their
constitutive elements. This way, practitioners reason, computers automate what
humans do as they recognise elements in a picture or scene. (Interestingly, the
distinction between those two, in an AI context, is generally considered non–essential, as it is ultimately always
the ‘real’ world that serves as a touchstone for accurate identification. From
a humanities perspective, this entails that the role of mediation is glossed
over.)
The
applications of computer vision research are extremely diverse. Models and methods
emerging from it are used in military and security systems (e.g. for the
purpose of surveillance), but also in medical software (such
as, image analysis tools used for diagnostics or to support operative
treatment). They
are integrated into equipment for navigation (for instance, in the development
of self-driving cars) and traffic control, and used in various other
commercial contexts (e.g. for quality
assurance and logistics in the manufacturing industries
and retail, or as part of consumer products for film and video production). Within
computer vision research, video retrieval, or the content-based retrieval of
digital moving images, has been an active area of inquiry since the beginning
of the century (with some projects, such as the well-known TRECVIC, running for almost two decades).
In recent years, methods developed in this field have also been repurposed to navigate
large databases of moving images; for instance, to support digital cinema
scholarship (e.g. Virginia Kuhn and her team’s VAT, or Barbara Flückiger et al.’s VIAN – both efforts that SEMIA builds
on) or for the development of movie recommendation systems (see e.g.
Bougiatiotis and Giannakopoulos 2018). However, the latter type of applications
are more marginal in both scale and societal impact, compared to the
aforementioned ones.
Feature
extraction, we mentioned, is a matter of describing images or image sections based
on information about their potentially significant visual characteristics. This
process results in representations, that are used in turn to classify them: as
computer vision algorithms are executed, decision rules are applied that
determine, on the basis of the extracted features, which categories the images
in a database belong to. This is true for task-specific algorithms, but also
for various machine-learning systems, such as neural nets. (See our
previous post for an explanation of the distinction between the two.) However,
in popular discourse on AI, this fact is often overlooked. As Anja Bechmann, a
digital sociologist, and Geoffrey C. Bowker, an authority in the field of
Science and Technology Studies (STS) observe (2019), it is often assumed that
in machine-learning applications, classification does not take place, because
categories are no longer constructed a
priori (4). In reality, however, AI heavily relies on statistics – a science
of classification. And for Bechmann and Bowker, classification is just “another
word for generalization” (ibid.).
For
this reason, classification raises a number of issues – at least, if we
consider it from a socio-political perspective. From the point of view of computer
vision, it is key that systems are designed and trained to generalise among
variations, as this increases the chance of them successfully identifying the
images in a database (see our
previous post). In this context, then, generalisation entails
(greater) potential – in the sense of (better) performance or (broader)
usability. However, for social and cultural critics, any form of generalisation
inevitably always results in a reduction
of potential. Labelling and classifying, which are common practice in many forms
of image analysis, involve the making of determinations as to what is or isn’t
relevant. (This is true even in cases where abstract, lower-level features are
extracted – the kind we focus on in SEMIA, as we discussed in our previous
post.)
And as STS scholar Adrian MacKenzie (2017) explains, any such determination
always operates according to a logic of reducing, rather than opening up, a
wider range of possibilities (7) – also at the very basic level of what is
taken to be visually significant. In the process, choices are made between
alternative options, even if the making of such choices is left to machines.
As
many before us have pointed out, this has profound socio-political
implications. Even machine learning systems that operate in largely
unsupervised ways (that is, systems that do not depart from a ‘ground truth’, or
human understanding of what their output values should be; see here for further elaboration)
necessarily rely to some extent on “institutionalized or accepted knowledges”,
along with their associated categories (MacKenzie 2017, 10). One reason for
this is that it is humans who feed them the data they extract information from.
And as Bowker and Star (1999) taught us decades ago, even the most broadly
agreed-upon categories are inevitably infused with bias. Such bias may derive
from the specific epistemic contexts in which those categories emerged (cf. Day
2014), but in AI systems, it is further re-enforced by the most popular
applications of its methods and tools. As we explained, the results of computer vision research
have been operationalised primarily for situations that involve the
recognition, and identification, of semantic entities, and specifically ‘objects’
(for instance, vehicles, humans and elements of the built environment, as in
traffic and transportation applications). Yet aside from the fact that as a
result, the algorithms involved have a keener eye for ‘things’ than other
classes (see Caesar, Uijlings and Ferrari 2018), they also normalise
classification practices that are often considered problematic.
As
the scholar-artist duo Kate Crawford and Trevor Paglen (2019) argue, questions
around the meaning of images – a topic of debate in philosophy, art history and
media theory for many decades – become all the more pressing in the context of machine
learning and the categorizations it involves. One reason for this is that in AI
systems, the logics behind labelling and classifying get increasingly shielded
from view. In many cases, even informaticians do not understand how exactly their
algorithms work, or how specific determinations have been made (e.g. Domingos 2015, xv-xvi). (Hence also
the growing interest today in ‘explainable AI’, or XAI: an emerging area of
machine learning that seeks to make
AI algorithms more transparent, also in response to the rights of those
whose lives are affected by them.) This black-boxed-ness becomes particularly
problematic if the images that are subjected to automatic interpretation also
feature persons. As people are
labelled in the manner of objects, Crawford and Paglen vividly illustrate, one encounters assumptions
about gender, race, ability and age that are not only unsubstantiated, but even
hark back to such nineteenth-century pseudo-scientific practices as phrenology
(likewise performed without the consent of those represented).
Promotional still for the exhibit Training Humans, curated by Kate Crawford and Trevor Paglen at the Fondazione Prada in Milan (Italy), which runs until 24 February 2020
As we
mentioned, both computer scientists and social and cultural theorists point in
this context to the composition and role of the datasets that are used for
training machine-learning algorithms, and that “shape the epistemic boundaries
governing how [such] systems operate” (Crawford and Paglen 2019). For
instance, DeVries
et al. (2019) recently discussed the
selective geographical coverage of items shown in the images contained in widely
accessible object-recognition training sets, arguing that they tend to be
Western-centric. (The authors focus in their study on images containing household
items, raising issues both with their selection, and with the objects’ relation
to the home environments in which they feature.) Crawford and Paglen (2019) however
argue that greater diversity in the selections made – a solution also DeVries
et al. propose – does not necessarily solve the problem of embedded bias. They
explain that one of the common properties of training sets’ architectures is
that they consist of three layers for the labelling, and sorting into
categories, of the images they contain: an overall taxonomy (“the
aggregate of classes and their hierarchical nesting”), the individual classes (“the
singular categories that images are organized into”) and finally, each
individually labelled image. Using the example of ImageNet, one of the most often-used
sets for training for object recognition (which also the network used in SEMIA relies
on [1]),
they demonstrate how each of those layers is “infused with
politics”, due to a reliance on problematic assumptions: about the existence of
specific concepts (as fixed and universal, and having internal consistency), about
the relation between concepts and images or appearance and ‘essence’, and about
the capability of statistics to determine (visual) ‘essence’ (Crawford and
Paglen 2019).
Another issue the authors touch upon but do not
elaborate, is that today’s computer vision systems, including neural nets, are
built to develop models for recognising differences between a closed set of
classes. The
result is that they work to generate binary results: either an image positively
belongs to class X, or it does not (Vailaya,
Jain and Zhang 1998). Above, we explained that from a
critical perspective, all algorithmic categorisation results in a
reduction of possibilities – for the simple reason that the allocation of a (semantic)
label always excludes the allocation of certain others. However, today’s
computer vision methods confound this situation, as they typically involve a
limited set of classes among which difference is established. Once again, this
raises profound issues; after all, it should not be assumed that a thing, but
certainly a person, either positively belongs to one category, or to another.
But
in the SEMIA context, it also hampers the development of an alternative to query-based
search. In explorative browsing, after all, the purpose is not to find
something that meets very specific criteria. (We elaborated on this in our previous
post.) Therefore,
it would in fact be preferable if the results a system generates were not
limited to what is identical or near-identical (as in: X either is a cat, or it is not) but also included
items on the spectrum of the somewhat
similar (X is like a cat). At
present, images in those ‘grey areas’ simply are not being classified (cf. Valaiya,
Figueiredo, Jain and Zhang 2001) and as such, the decision as to whether they
might be relevant are also taken out of the user’s hands. The reason is that
the algorithms used are optimized to achieve the highest possible level of
certainty in a process of identification.
Some
clues as to how this situation came to be can perhaps be found in the development
history of computer vision. To explore this possibility, we briefly trace this
history, distinguishing in the process between three (broad) developmental
phases. Our purpose here is to discuss when and how choices that still
determine how computer vision is practiced today, got introduced. Arguably,
this can help reveal why we are currently
left with assumptions and views that over time got increasingly
taken-for-granted, but are certainly worth challenging – within the SEMIA
context, but perhaps also beyond.
In
the very early years of computer vision, in the 1960s, the ultimate objective
was to build ‘vision systems’ that would allow the planning and reasoning
components then prominent in AI to be used to reason about the real world. As we
pointed out before, the field’s pioneers, such as Seymour
Papert and
his colleagues at MIT and elsewhere, were rather too optimistic about how
quickly this task might be accomplished.[2] Much of this
early work revolved around the idea that the world around us consists of
objects, and that by identifying those objects, we can understand the world. For
this reason, specific approaches focused on decomposing images into lines, and
developing methods for extracting from those lines contiguous shapes (that is,
shapes with common borders) that could then be matched to templates of known
objects (Roberts 1963). Throughout this first phase of the field, which
approximately lasted until the late 1990s, the dominant paradigm was focused on
formal geometric description. Over time, approaches for describing and matching
shapes became more mathematically sophisticated, but even so, they still relied
on analysis methods designed by humans, as well as manually specified matching
or decision rules.
The second phase we
identify began in the late 1990s and early 2000s. It is marked by the emergence
of feature-based approaches, which relied on mathematically complex algorithms
for finding and describing local areas or points of interest in images (Mundy
2006). The algorithms used at the time were still designed by humans; however, they
were quite flexible in terms of how features got extracted from realistic
images, and this made it possible for systems to automatically learn the templates
(or models) describing objects from sets of images. As such, they heralded a
larger role for machine learning in computer vision. For the user, these
developments removed the burden of having to specify decision rules; however, they
also shifted this burden to finding and specifying sets of images
representative of given objects. Moreover, due to the choice of learning
paradigm that was made at the time – one of discriminative learning – it
additionally placed a burden on the image set as such, in its entirety.
‘Discriminative’
(learning) models, as opposed to ‘generative’ models, do not centre in the analysis
process on the characteristics of the objects themselves, but rather on the
characteristics that make them different
from other objects, within the
context of the dataset provided (see e.g. Ng and Jordan 2001). In other words,
the learnt characteristics of an apple, for example, will be different if the
only other object represented in the dataset is an orange (in which case they
can be distinguished from each other based on colour alone) than if the dataset contains a rich and varied
collection of objects. After all, something red and round could be an apple,
but it might as well be a traffic light. In terms of the aforementioned
‘burden’ on the dataset, this also means that while two classes may be easy
enough to distinguish based on canonical examples, it becomes more difficult
when alternative forms or views also come into play. For this reason, larger
and more varied datasets necessitate a more detailed description of the objects
in them. And, due to this interaction between algorithms’ performance and the
datasets they are trained on, the field of computer vision has since
also begun to work with increasingly large datasets, featuring more varied
selections of classes (as also exemplified by DeVries et al. 2019).
The increase in
size and diversity of datasets in turn places an enormous constraint on the
representational power of the chosen features. Accurately distinguishing
between very similar classes, indeed, requires a feature representation that is
rich enough to make this possible. This brings us to the third, and current,
phase of computer vision, inaugurated by the resurgence of representation or deep
learning algorithms in the early 2010s. Rather than relying on sophisticated
mathematical, but manmade, algorithms, such methods use algorithms that learn the
feature representation for a given dataset in a way that optimises their performance.
Learning algorithms are used in both the feature extraction component of the
process (the stage when image areas are transformed into descriptions or representations) and in that of object model construction
(when a mathematical model is generated to describe the featured objects). Both
are fully data-driven, and because of their reliance on a discriminative
learning paradigm, will focus on what makes the classes in the dataset
different from each other, rather than to learn generalisable characteristics
of the objects. This focus has ultimately led to better performance on a range
of computer vision tasks, but at the same time, it has aggravated some of the
political issues discussed above. (After all, are any categories quite as mutually exclusive as the system makes them
out to be?)
The typically narrow manner in which computer vision algorithms
recognise objects, along with their strong focus on semantic recognition (see our previous
post), inevitably impact on their potential for reuse. This is
significant also in the SEMIA context, where we seek to enable users to browse
– rather than search – large moving image collections, and have therefore had
to reckon with the consequences of the abovementioned developments. To conclude
this post, we briefly discuss how they affected our process, and what we did to
counteract the constraints they imposed.
In the computer vision field, a great deal of effort has
been taken to improve search methods, with a specific focus on increasing performance
in the area of retrieval. In retrieval, the goal is to return matches within a
given database of (moving) images, based on a query. Typically, the performance
of systems designed for this task is measured in terms of precision and recall.
‘Precision’, in this context, describes the proportion of results in the set of
returned results that are deemed ‘correct’. Recall, in turn, specifies which proportion of all possible ‘correct’
results was contained in the set of returned results. A key notion in measuring
precision and recall, in other words, is that of ‘correctness’: for a given
query, there are results that are correct and others that are not. In order to
produce such judgments, computer vision algorithms rely on labelled data. Through its
labelling, the data reveals what is considered correct and what isn’t, as understood
by the developers of algorithms and training datasets and incorporated into
their design.
In the academic, experimental setting in which computer
vision algorithms are developed, the aim is to maximise performance on metrics
such as precision and recall. However, regardless of how problematic this is from
an epistemic perspective (correctness, in this context, being a highly relative
concept) or a socio-political one (consider, once again, the bias ingrained in
the abovementioned practices of labelling), one might argue also that for
practical implementations that involve a good deal of user interaction, it might
not even be the main priority.
In search, the emphasis is typically on precision, because
in submitting a query, a user tends to prefer a situation whereby the first few
results are very close matches, in the sense of ‘correctness’ as discussed
above. A searcher will much more easily notice low-precision cases (those
results that do not match the query) than low-recall cases, where the missing
results are typically ‘unknown unknowns’ (results one did not know of
beforehand, and therefore does not miss). For browsing purposes in contrast, higher
recall tends to be more desirable, as it presupposes a user seeking to explore the
diversity of the materials in a database. If one is shown only those items that
represent slight variations of the same, narrowly defined concept, this simply
isn’t possible. Developing computer vision algorithms, then, involves a
trade-off between maximising precision, and maximising recall – or otherwise, finding
a balanced ‘average’ between the two.
In all of these cases, however, developers are forced to rely
on pre-existing definitions of concepts and their scope. Unless, of course, they
choose not to go for classification
into concepts at all, and rather express
similarity as a ‘continuous’ concept (instead of one of ‘match’ or ‘mismatch’).
Arguably, this is exactly what we did in the SEMIA case.
We previously discussed how we
decided in the project to work outside the existing framework for feature
extraction, which entailed that instead of designing (or having the system
automatically learn) decision rules for which classes items belong to, we
relied on the ‘raw’ (that is, lower level, syntactic) features. In practice, we
used those features to map each item to a point in a contiguous ‘feature space’
(see here for an explanation of
this notion that extends beyond the field of computer vision). So, while we
still relied in the extraction process on algorithms trained for object recognition, we no longer used them to this end. By thus foregoing classification using
(narrow) concepts, and describing visual content based on features instead of
categories, we relied on an expression of similarity as a continuous concept,
rather than a binary one. For the user of our interface, this will entail that browsing
or exploring becomes a form of ‘walking through’ a feature space, whereby each
next step is determined by the visual similarity between items rather than
their semantic labelling.
Of course, this approach still builds on one that is commonly used for retrieval purposes; however, we do not evaluate it using performance measures relying on labels, that require a definition of what either is or isn’t ‘correct’. Instead, we focus on the user and their experience, but also their ability to explore a database or collection, or get inspired by the material they encounter. In the following posts in this series, we explore further how we have worked with the features thus extracted to design an interface for making the images in our repository accessible to users.
– Eef Masson and Nanne van Noord
Notes
[1] The results we will be sharing via our prototype interface (to be discussed in an upcoming post on this blog) are the outcome of an analysis based on (many) more than 1,000 classes. See Mettes, Koelma and Snoek 2016 for more information.
[2] There is a famous story, which seems to have some basis in reality, about a 1966 project in which students were asked to build a significant part of such a vision system in a single Summer; see Papert 1966. Yet it soon became clear that ‘solving the vision problem’ might not be quite as trivial as it appeared to be.
Bougiatiotis,
Konstantinos, and Theodoros Giannakopoulos. 2018. “Enhanced Movie Content
Similarity Based on Textual, Auditory and Visual Information.” Expert Systems With Applications 96:
86-102. Doi: 10.1016/j.eswa.2017.11.050.
Bowker, Geoffrey C., and Susan Leigh Star. 1999. Sorting Things Out: Classification and Its
Consequences. Cambridge, MA: MIT Press.
Caesar, Holger, Jasper Uijlings, and Vittorio Ferrari. 2018. “COCO-Stuff: Thing and Stuff Classes in Context.” In 2018 IEEE conference onComputer Vision and Pattern Recognition, n.p. Computer Vision Foundation, 2018.
Day, Ronald. 2014. Indexing it All: The Subject in the Age of Documentation, Information, and Data. Cambridge, MA: MIT Press.
DeVries, Terrance, Ishan Misra, Changham Wang, and Laurens van der Maaten.
2019. “Does Object Recognition Work for Everyone?” In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR) Workshops, 52-59. Available
from arXiv:1906.02659.
Mundy,
Joseph L. 2006. “Object Recognition in the Geometric Era: A
Retrospective.” In Toward Category-Level
Object Recognition (volume 4170 of Lecture
Notes in Computer Science), ed. by Jean Ponce, Martial Hebert, Cordelia
Schmid, and Andrew Zisserman, 3-28. Berlin Heidelberg: Springer.
Papert, Seymour. 1966 “The
Summer Vision project.” Unpublished document. Available from https://dspace.mit.edu/handle/1721.1/6125.
Pylyshyn,
Zenon. 1999. “Is vision continuous with cognition? The case for cognitive
impenetrability of visual perception.” Behavioral and Brain Science 22,
no. 3: 341-423. See here for a reprint in
pdf.
Roberts, Lawrence G. 1963. “Machine
Perception of Three-Dimensional Solids.” Unpublished PHD
dissertation, Massachusetts Institute of Technology, Cambridge (MA). Available
from https://dspace.mit.edu/handle/1721.1/11589.
Szeliski, Richard. 2009. Computer Vision: Algorithms and Applications. London: Springer.
Vailaya,
Aditya, Mário A.T. Figueiredo, Anil K. Jain,
and Hong-Jiang Zhang. 2001. Image
Classification for Content-Based Indexing. IEEE
Transactions on Image Processing 10, no. 1: 117-130. Doi: 10.1109/83.892448.
Zeimbekis, John, and Athanassios Raftopoulos, eds. 2015. The Cognitive
Penetrability of Perception: New Philosophical Perspectives.
Oxford: Oxford University Press.
As the SEMIA project reaches its final
stage, we will be releasing a few more posts in which we report on what we did,
and learnt, over the course of the past two years.
In the first two items to appear,
members of the University of Amsterdam team present some reflections on what
developments in the field of computer vision can do for access to moving image
collections. To begin with, we discuss the different ways of approaching such
collections, and report on how we tweaked existing methods for feature
extraction and analysis in order to offer users a more explorative alternative
to search (currently still the dominant access principle). Next, we delve a
little more deeply into the forms of classification this involves, the issues
they raise, and how they impacted on our process. In a third post, the Amsterdam University of Applied Sciences
team discuss their experience of building an interface on top of the
functionality for image analysis that our computer scientist developed. And in
a final one, we introduce four SEMIA-commissioned projects in which visual and
sound artists use the data we
generated in the feature analysis process, to devise (much more experimental)
alternatives for engaging audiences with the archival collections we sampled
for our purpose.
In this first item, we expand on our project objectives (as introduced on
the About
page on this site) elaborating on our vision for an explorative approach to
collection access, and discuss the implications for feature extraction and
analysis.
~
As we previously
explained, our purpose in the SEMIA project was
to find out how users might access moving images in digital form, not by searching
for specific items (and in hopes of fulfilling a given need, in research or reuse)
but in a more ‘explorative’ way, inspired in the process by the visual
appearance of the films or programmes in a collection. To this end, we adapted methods
and tools developed in the field of computer vision. This allowed us to extract
sensory information from discrete objects in our database, combine it, and thus
establish relations between said objects (a process we explain in a little more
detail in our following post). Subsequently, we visualised the relations that
emerged and built an interface around them. (For the more technically inclined: one should imagine this step
as converting
high-dimensional representations into a 2D representation while preserving the
closeness or distance between the object features. The role of representation, likewise, will
be touched upon in our next post.) In extracting
image information, we focused on colour, shape, texture (or in computer vision
terms, ‘visual complexity’ or ‘visual
clutter’) and movement (or ‘optical
flow’) in the fragments in our
purpose-produced repository.
In the past few decades, access to the
collections of (institutional) archives, whether analogue or digital, has
tended to rely on written information, often in the form of item-level catalogue
descriptions. Increasingly, such information is no longer stored in separate
databases, but integrated into collection management systems that also contain
digitised versions of related still images and/or the films or programmes
themselves. In addition, records are more often part of larger networks, in
which they can be cross-referenced (see e.g. Thorsen and Pattuelli 2016). But as a rule, patrons still need to approach the works they
are looking for through associated descriptions, which are necessarily verbal. To this end, they need to search
a system by formulating a query, using terminology that aligns with that used
in the database.
Elsewhere on this site, we already touched upon some of the issues with this principle of access-by-search. On the one hand, it forces users to approach collections from the perspective of those who identified and described them, and on the basis of their prior interpretations. As it happens, the categories that moving image catalogues work with, and that inform such efforts, tend to be quite restrictive in terms of the interpretive frameworks they adhere to. Oftentimes, they cluster around productional data, plot elements, standardised labels for the activities, people or places featured (using set keywords and proper names) and/or genre identifiers (cf. Fairbairn, Pimpinelli and Ross 2016, pp. 5-6). In contrast, the visual or aural qualities of the described items – after all, difficult to capture verbally – tend to remain undocumented.[1] For historic moving images, this is problematic, as they are often valued not only for the information they hold but also for their look and ‘feel’. On the other hand, search infrastructures also operate on the built-in assumption that users are always looking for something specific. And moreover, that they can put into words what it is they are looking for – in the form of a query. Over the years, research on the topic has actually provided a great deal of evidence to the contrary (see e.g. Whitelaw 2015).
A
query, in the words of literary scholar and digital humanist Julia Flanders (2014),
is a “protocol or algorithm invoking […] content via a uniform set of
parameters from an already known set of available data feeds or fields” (172). The
phrase ‘already known’, in this sentence, is key, as it draws attention to the
fact that database searchers need to be familiar from the outset with the (kinds
of) datasets a database holds, in order to be able to use them to their
advantage. In other words, search interfaces are more about locating things, than about finding out
what the repositories they interface to, might contain. For this reason,
designer, artist and interface scholar Mitchell Whitelaw (2015) calls them
“ungenerous”: they withhold information or examples, rather than offering them
up in abundance. Arguably, this restricts users in terms of what they may
encounter, which kinds of relations between collection or database objects they
can establish, and which kinds of insights about them they can gain.
The most
common (and practical) alternative to searching collections is browsing them
(Whitelaw 2015). Although definitions of this term diverge, authors tend to
agree that it entails an “iterative process” of “scanning […] or glimpsing […]
a field of potential resources, and selecting or sampling items for further
investigation and evaluation” (ibid.).
Browsing, in any case, is more open-ended than searching; arguably, one can
even do it without a specific goal in mind. For Whitelaw, practices of browsing
therefore challenge instrumentalist understandings of human information
behaviour in terms of an “input-output exchange” – understandings that are
quite common still in such disciplines as information retrieval (ibid.). Others before him have argued
that because of this open-endedness, they also foster creativity (e.g. O’Connor
1988, 203-205) – a key objective, indeed, of the SEMIA project. In an upcoming
article, we propose that this is due at least in part to the potential it
offers for serendipitous discovery: for sudden revelations that occur as a
result of unexpected encounters with (specific combinations of) data – or as in
our case, items in a collection or database (Masson and Olesen forthcoming).
A connection made serendipitously: still from media artist Geert Mul’s Match of the Day (2004-ongoing) [click the image to view a fragment]
To
enable browsing, Whitelaw (2015) argues, we need to “do more to represent the
scale and richness of [a] collection”, and at the same time offer multiple
inroads into it. We can do this for instance by devising new ways for users to establish
relationsbetween objects. Flanders, building on a suggestion by Alan Liu, proposes
that in thinking about the constitution of digital collections, we adopt a
‘patchwork’ rather than a ‘network’ model. This invites us to view them not as
aggregations of items with connections between them that “are there to be
discovered”, but as assemblages of things previously unrelated but somehow
still “commensurable” – in the sense that they can be mutually accommodated in
some way (2014, 172). If we do this, a collection becomes “an activity” constantly performed, “rather
than a self-evident thing or a set” (ibid.). Within the SEMIA context, we act
in the assumption that the sensory features of collection items can serve as a
means (or focal point) for making them ‘commensurable’. The basis for
commensurability, here, could be likeness, but potentially also its opposite –
because in exploring images on the basis of their visual features, the less
similar or the hardly similar may also be productive. Arguably, the relations this suggests complement those
that traditional archival categories already point to, and thereby allow us, in
Whitelaw’s words, to present more of a collection’s richness.
In recent
years, archival institutions have experimented with the use of various artificial
intelligence tools to enrich their collection metadata, such as technologies
for text and speech transcription.[2]
No doubt, such initiatives are already contributing towards efforts to open up their
holdings to a range of users. But when it comes to broadening the variety of possible ‘entry points’ to
collections, visual analysis methods are especially promising. First, because they
may help compensate for the almost complete lack of information, in the current
catalogues and collection management systems, on the visual characteristics of archival
objects. At the very least, extracting visual information and making it
productive as a means for exploring a database’s contents may allow for
previously unrecoverable items (such as poorly metadated ones) to become
approachable or retrievable – and in the process, very simply, ‘visible’. A
second, related reason is that such increased visibility may in turn entail
that objects are interpreted in novel ways. Specifically, it can alert users to
the potential significance of (perhaps previously unnoticed) sensory aspects of
moving images, thus reorienting their interpretations along previously ignored
axes of meaning. Interesting in this context is that, as we rely on visual
analysis, we may not have to trust the system to also settle on what exactly
those aspects, or the connections between them, might represent, or even ‘mean’.
In principle, then, visualisation of our analyses might also offer an
alternative to traditional catalogue entries that verbally identify, and
thereby (minimally) interpret, presumably meaningful entities.
However,
exploiting this potential does require significant effort, in the sense that
one cannot simply rely on existing methods or tools, or even build on all of
their underlying principles. As it happens, much research in the field of
computer vision is also focused on identification tasks, and specifically, on
automating the categorisation of objects. (We discuss this point further in our
next post.) Visual features such as colour, shape, movement and texture are
quite abstract – unlike the sorts of categories that catalogues, but also image
recognition applications, tend to work with. For this reason, using them as the
starting point for a database exploration entailed that our computer scientist had
to tweak existing analysis methods. But in addition, it also meant that the
team needed to deviate from its original
intent to rely primarily on deep
learning techniques, and specifically on the use of so-called ‘artificial
neural networks’ (or neural nets), which learn their own classification
rules based on the analysis of lots of data.
The
first of these measures was basically that in the feature extraction process
(which we also discuss in a little more detail in a subsequent post), we
stopped short of placing the images in our database in specific semantic classes.
In the field of computer vision, a conceptual distinction is often made between
image features at different ‘levels’ of analysis. Considered from one
perspective, those levels concern the complexity of the features that are
extracted. They range from descriptions of smaller units (such as pixels in
discrete images) to larger spatial segments (for instance sections of images,
or entire images) – with the former also serving as building blocks for the
latter (the more complex ones). But from another, complementary perspective,
the distinction can also be understood as a sliding scale from more ‘syntactic’
to more ‘semantic’ features. For purposes of object identification, semantic
ones are more useful, as they represent combinations of features that amount to
more or less ‘recognisable’ entities. For this reason, computer vision
architectures such as neural nets are trained for optimal performance at the
highest level of analysis.[3] In
SEMIA, however, it is precisely the more ‘syntactic’ (or abstract) features
that are of interest.
So, our computer scientist, while inevitably having to
work with a net trained for analysing images at the highest semantic level
(specifically, ResNet-101, a Convolutional Neural Network or CNN), chose
to scrape information rather at a slightly lower one (also a lower ‘layer’ in
the network itself): there where it generally contains descriptions of sections
of the objects featured in them. At this level, the net ‘recognises’ shapes,
but without relating them to the objects they are supposedly part of (so that
they can be identified).[4] Arguably,
this allows users more freedom in determining which connections between images –
made on the basis of their shared, or contrasting, features – are relevant, and
how. (In our upcoming article, we consider this assumption more closely, and
also critique it; see Masson and Olesen forthcoming.) Hopefully, this also
makes for a more intuitive exploration, less restrained by conventional,
because semantically significant, patterns in large aggregations of moving
images.
The second measure we took to ensure a sufficient level of
abstractness in the relations we sought to establish, was to not rely
exclusively on methods for machine learning (and specifically, deep learning;
see here for the difference).
For some of the features we were concerned with, we reverted instead to the use
of task-specific algorithms. As we previously
explained (and
will discuss further in our next post), early methods for computer vision used
to involve the design of algorithms that could execute specific
analysis tasks, and were developed to extract given sets of features. More recently,
the field has focused more radically on the design of systems that enable automatic
feature learning. Such systems are not instructed on which information to
extract, but instead, at the training stage, make inferences on the topic by
comparing large amounts of data. This way, they infer their own decision rules
(see also our upcoming post). As we explained, training, here, is geared very
much towards identification; that is, analysis at the semantic level. For this
reason, we decided to only use the neural net to extract information about shape
(or rather: what we, humans, perceive as such) – the area where it performed
best as we scraped lower-level, ‘abstract’, information. To isolate colour and
texture information, we reverted to other methods: respectively, the construction
of colour histograms (in CIELAB colour space [5]) and the
use of a Subband Entropy measure (see Rosenholtz, Li, and Nakano 2007). Movement information was extracted
with the help of an algorithm for measuring optical flow.[6]
This way, we could keep features apart, so as to ultimately make them
productive as parameters for browsing.
Query shots from the SEMIA database, along with four of their ‘nearest neighbours’ (closest visual matches) in the shape, colour, movement, and visual complexity feature spaces [provided by project member Nanne van Noord]
Yet
as we learnt, even if feature extraction is done with a minimum of human
intervention in the labelling of images (and image sections), we can never
truly cancel out the detection of semantic relations altogether. This is
hardly surprising, as it is precisely the relations between low-level feature
representations and objects that have long since been exploited to detect
semantic relations and objects – even in very early work on computer vision. (Our
computer scientist tends to illustrate the underlying logic or intent as
follows: oranges are round and orange, so by detecting round and orange
objects, we can find oranges.) Therefore, some feature combinations are simply
too distinctive not to be detected with our chosen approach – even if we do our
best to block the algorithms’ semantic ‘impulse’ (as the first and second image
cluster above make clear).[7] At
the same time, our examples show that the analysis of query images also highlights
visual relations that initially seem more ‘illegible’, and therefore, invite
further exploration. In this sense, our working method does yield surprising
results or unexpected variations. (Such as, the connection, in the first series
above, between the movement of an orchid’s petals in the wind, and those of a
man presumably gesticulating while speaking.)
In the course of the project, our efforts have been geared at all times towards stimulating users to explore those less obvious connections. This way, we hope not only to significantly expand the range of metadata available for archival moving images, but also to allow for a revaluation of their sensory dimensions – also in the very early (‘explorative’) stages of research and reuse.
– Eef Masson
Notes
[1] Oftentimes,
archival metadata do specify whether films or programmes are in black and white
or colour, or sound or silent, and they may even name the specific colour
or sound systems used. But they generally do not provide any other
item-specific information about visual or aural features.
[2] For example, the Netherlands
Institute for Sound and Vision, our project partner, has recently been
exploring the affordances of automated speech recognition.
[3] Many thanks
to Matthias Zeppelzauer (St. Poelten University of Applied Sciences) for
helping us gain a better understanding of these conceptual distinctions.
[4] For more on how
neural nets specifically ‘understand’ images, see also Olah, Mordvintsev, and
Schubert 2017.
[5] The
histograms further consisted of 16 bins for the description of each colour dimension (resulting in a feature
representation of 4096 dimensions).
[6] Movement
information was described by means of a histogram of the optical flow patterns.
Angle and magnitude were separately binned for each
cell in a three by three grid of non-overlapping spatial regions (an approach
akin to the HOFM one described
in Colque et al. 2017). The procedure
for colour, texture and movement information extraction was always applied to five (evenly
spaced) frames per fragment (shot) in our database.
[7] Exact matches rarely occur, because for the purposes of the project, the detection settings were tweaked in such a way that matches between images from the same videos were ruled out. (Therefore, only duplicate videos in the database can generate such results.)
References
Colque, Rensso V.H.M., Carlos Caetano, Matheus T.L. De Andrade, and William
R. Schwartz. 2017. “Histograms of Optical Flow Orientation and Magnitude and
Entropy to Detect Anomalous Events in Videos.” IEEE Transactions on Circuits and Systems for Video Technology 27,
no. 3: 673-82. Doi: 10.1109/TCSVT.2016.2637778.
Flanders, Julia.
2014. “Rethinking Collections.” In Advancing
Digital Humanities: Research, Methods, Theories, ed. by Paul Longley Arthur
and Katherine Bode, 163-174. Houndmills: Palgrave Macmillan.
Masson, Eef, and
Christian Gosvig Olesen. Forthcoming [2020]. “Digital Access as Archival Reconstitution: Algorithmic
Sampling, Visualization, and the Production of Meaning in Large Moving Image
Repositories.” Signata: Annales des sémiotiques/Annals of Semiotics 11.
O’Connor, Brian C. 1988. “Fostering
Creativity: Enhancing the Browsing Environment.” International Journal of Information Management 8, no. 3: 203-210. Doi:
10.1016/0268-4012(88)90063-1.
Rosenholtz, Ruth, Yuanzhen Li, and
Lisa Nakano. 2007. “Measuring
Visual Clutter.” Journal of Vision 7, no. 17. Doi: 10.1167/7.2.17.
Thorsen,
Hilary K., and M. Christina Pattuelli. “Linked Open Data and the Cultural
Heritage Landscape”. In Linked Data for Cultural Heritage, ed. by Ed Jones and Michele
Seikel, 1-22. Chicago: ALA Editions.
Earlier this month, on 2 May 2019, project member Eef Masson presented the SEMIA team’s work at Utrecht University’s Transmission in Motion (TiM) seminar. TiM is a research initiative that brings researchers from across disciplines together with artists and others outside the academy, in order to discuss how the centrality of movement, motion and gesture to contemporary media and media technologies foregrounds the performativity of practices of transmission and the materiality of mediation. This year’s seminar focuses on questions about Experiment/Experience, and aims to “unpack aspects of the intimate relationship between experience and knowing and point to meaning as material practice of experience”.
In her lecture, entitled “Experience and Experimentation in the Sensory Moving Image Archive Project”, Eef looked at how experimentation fed into the SEMIA research: how it served to continually modify not only the project team’s objectives in tool development, but also its understanding of the implications of various choices made in the process. Specifically, she discussed the obstacles the team ran into (practically as well as conceptually) as it sought to achieve its goal, in working towards an alternative to semantic search, to delay the moment in time when meaning gets assigned to the objects in a collection, archive or database. In doing so, she reflected on how the chosen experimental approach highlighted the need, at several points in the project, to challenge, undermine or counteract a ‘state of the art’ – both in the field of computer vision, and in practices of interface design (as it happens, two fields where practitioners tend to heavily rely on experimentation).
In follow-up to the seminar session, students from Utrecht’s research MA in Media, Art and Performance Studies wrote blog posts, reacting to the lecture. They contributed the following reflections:
As we approach the Sensory Moving Image Archives Symposium we have now finalized the schedule and the full list of speakers for the event and put it together as a preliminary program. Abstracts and speaker bios will be added next month. The details of the preliminary program are available below and can be downloaded in pdf format here.
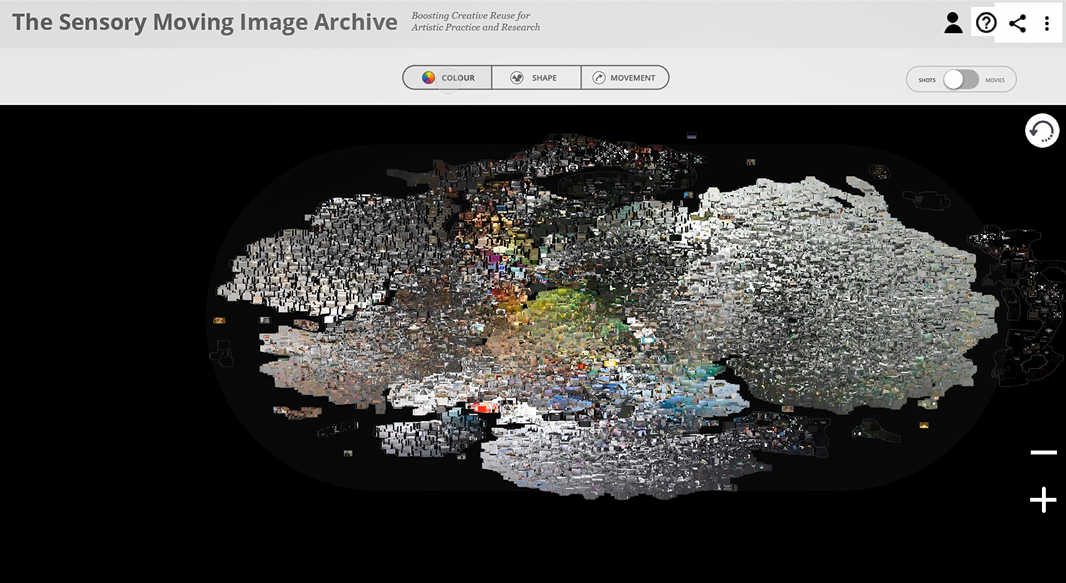
In addition to publishing the program we also share a first glimpse of the Sensory Moving Image Archive interface prototype (see below) prepared by Maaike Van Cruchten and Frank Kloos at the Amsterdam University of Applied Sciences. The prototype will be presented during the symposium.
There is still a limited number of seats available for the event. Please register by e-mailing Christian Olesen at c.g.olesen_at_uva.nl.
Dates: February 25-26, 2019
Location: University Library Singel, Singel 425, 1012 WP Amsterdam
Monday 25 February, 9:30 – 17:45
Doelenzaal, 09:30 – 12:35
Introduction Symposium Day, 09:30 – 10:00
Giovanna Fossati (University of Amsterdam/Eye Filmmuseum), Eef Masson (University of Amsterdam) & Christian Olesen (University of Amsterdam) – “An Introduction to the SEMIA Project and Symposium”
Session 1 – Digital Methods in Media Studies and Media History, 10:00 – 11:45
Lecture 1, 10:00 – 10:45
Catherine Grant (Birkbeck, University of London), “Film and Moving Image Studies: Re-Born Digital and Audiovisual? Some Updated Participant Observations”
Panel 1, 10:45 – 11:45
Flueckiger, Barbara (Universität Zürich) & Gaudenz Halter (Universität Zürich), “Deep-learning Tools for the Visualization of Film Corpora”
Marcel Worring (University of Amsterdam) & Nanne van Noord (University of Amsterdam), “Sensory Features for Archive Exploration”
Coffee & Tea Break, 11:45 – 12:15
Demo Session Presentation 1, 12:15 – 12:35
SEMIA Prototype Presentation
Maaike van Cruchten (Amsterdam University of Applied Sciences), Frank Kloos (Amsterdam University of Applied Sciences) & Harry Van Vliet (Amsterdam University of Applied Sciences), “Prototyping for the SEMIA project”
George Wright (BBC R&D), Cassian Harrison (Channel Editor, BBC4), title t.b.c.
Panel 2, 14:45 – 16:15
Johan Oomen (Netherlands Institute for Sound and Vision), “Image Recognition in CLARIAH and the Open Archive Project”
Pesek, Krystof (Digital Laboratory of Narodni filmovy archiv, Prague), “Detecting Duplicates of Moving Image Representations”
Wegter, Rob (University of Amsterdam), Samarth Bhargav (University of Amsterdam), Nanne van Noord (University of Amsterdam), Julia Noordegraaf (University of Amsterdam), and Jaap Kamps (University of Amsterdam), “Deep Learning as a Tool for Early Cinema Analysis: Experiences with Detecting Intertitles in Silent Film”
Coffee & Tea Break, 16:15 – 16:45
Session 3 – Looking Ahead: From Scholarly to Artistic Visual Analysis, 16:45 – 17:30
Mitchell Whitelaw (Australian National University), title t.b.c. – remote participation via Skype
Panel 4, 10:45 – 11:45
Mayr, Eva (University of Krems, danubeVISlab), Adelheid Heftberger (German Federal Archive), Florian Windhager (Danube University Krems) & Marian Dörk (Institute for Urban Futures, University of Applied Sciences Potsdam), “Projecting Film Archives – Lessons Learned from the Visualization of Cultural Heritage Collection Data”
Huurdeman, Hugo (University of Amsterdam) and Liliana Melgar Estrada (Netherlands Institute for Sound and Vision), Jasmijn Van Gorp (Utrecht University), Julia Noordegraaf (University of Amsterdam), Roeland Ordelman (Netherlands Institute for Sound and Vision), “Looking Beyond the Picture – Enhancing Sensemaking of Audiovisual Materials in the Media Suite”
Coffee & Tea Break, 11:45 – 12:15
Demo Session Presentation 2, 12:15 – 12:35
The Movie Mirror Demo Presentation
Studio Louter, “The Movie Mirror”
Potgieterzaal/Doelenzaal Foyer, 12:35 – 13:45
Demos & Lunch
Demos
SEMIA prototype and demonstration video
The Movie Mirror (Studio Louter)
DRAFT (UvA)
Doelenzaal, 13:45 – 15:30
Session 5, 13:45 – 15:30: Data Visualization and Experimental Film and Video
Lecture 5, 13:45 – 14:30
Mirka Duijn (Media Artist & Documentary Filmmaker, HKU University of the Arts Utrecht), title t.b.c.
Panel 5, 14:30 – 15:30
Carleen Maur (University of South Carolina), “Invisible Archives: Tracing the Use of Formal Archival Strategies in the Video, Patterns, to remember Stonewall”
Eric Theise (Software Developer & Artist), “If Maps: Cartographic Sketches Powered by Experimental Films”
Coffee & Tea break: 15:30 – 16:00
Session 6 – Scholarly and Artistic Practices of Data Visualization: Conclusions and Final Discussion, 16:00 – 17:30
Lecture 6, 16:00 – 16:45
Steve F. Anderson (University of California, Los Angeles), “Every Image a Database”
Final Discussion Day 2 and Wrap-Up Symposium, 16:45 – 17:30
We are very happy to announce that SEMIA will be organizing a two-day international symposium on visualization, exploration and reuse of moving image data next year in February, at the University of Amsterdam. The call for papers can be found below and is downloadable in pdf format here.
CfP: Sensory Moving Image Archives – Visualization, Exploration and Reuse of Moving Image Data
Date: 25-26 February, 2019
Location: Doelenzaal, University Library, University of Amsterdam, Singel 425.
Registration: Entrance is free but seats are limited, so please register by emailing c.g.olesen_at_ uva.nl.
The international two-day symposium Sensory Moving Image Archives: Visualization, Exploration and Reuse of Moving Image Data comes out of the research project TheSensory Moving Image Archive: Boosting Creative Reuse for Artistic Practice and Research (SEMIA, 2017-2019). Working with diverse archival material from Eye Filmmuseum and the Netherlands Institute for Sound and Vision, SEMIA develops alternative ways of exploring moving image archives by analyzing data concerning visual features – such as colour, movement and shape. To achieve this, SEMIA has trained deep-learning networks for extracting sensory data from moving images and developed an interface for exploring the results. The project’s outcomes will support alternative ways of accessing collections and facilitate new forms of reuse based on sensory data.
In pursuing these goals, the project seeks to challenge the limitations of traditional text-based search. In recent years, three groups in particular have expressed a need for this – and it is these groups the symposium targets. They are scholars and scientists (including media historians, museum and archival scholars, digital humanities scholars and computer scientists), artists working with moving image or cultural heritage collections, and archivists (including media archivists and cultural heritage professionals more broadly). Taking SEMIA’s results as its starting point and test case, the symposium offers a platform for exchange between perspectives from those different groups, and the fields they represent. The program will consist of invited presentations and papers accepted through an open call. Scholars, professionals and practitioners from all groups are strongly encouraged to submit proposals.
The programme committee for the symposium invites contributions in the following areas (but will also consider other relevant topics):
Media Historiography and Digital Humanities
Data-driven visual methodologies for the analysis of visual culture (Rose 2013), in different areas of the humanities
Examples of the exploration of moving image and cultural heritage data, for instance in the lineage of Exploratory Data Analysis (Tukey 1977) or Cultural Analytics (Manovich 2009)
Approaches in film studies engaging with data visualization as a form of deformative criticism (Ferguson 2017) or new cinephilia (Habib 2015)
Heritage Studies
Interfaces for heritage collections that challenge text-based search and retrieval, for instance “generous” interfaces (Whitelaw 2015) or forms of humanistic interface design (Drucker 2013)
Processes for and experiences in designing exploratory interfaces for heritage collections, specifically prototyping and user testing
Computer Science
Deep-learning and/or feature engineering for visual analysis of moving images
Computer science approaches tailored to the analysis of subjective attribute data (rather than object recognition or scenes)
Media Art
Media art projects and practice-based research exploring the affordances of non-evidentiary algorithmic approaches to moving image data analysis and visualization
Practices of found footage, expanded cinema and moving image archive appropriation involving data analysis and visualization
Media Archiving
The integration of computer-generated (sensory) moving image data in media asset management systems and/or moving image archive databases
Reuse of (sensory) moving image data for TV production and in journalism
Submission guidelines:
Please submit an abstract of 300 words and a short bio of 50 words, in pdf format, by emailing c.g.olesen_at_uva.nl before 23 November.
What do people look for, as they access large collections of digitized films, and how do they want to conduct their explorations? Those were the central questions of the second SEMIA workshop, that took place at the offices of project partner Studio Louter, on 28 March 2018.
Compared to the first workshop, this second one took a much more hands-on approach. The abovementioned questions had to be translated into creative assignments, that would be appealing for a diverse audience of media scholars, media artists and creative industry professionals, and professionals concerned in their daily practice with the interests of museum visitors. Participants for the workshop were selected from those four groups.
In the first assignment of the day, the attendees, sat in small groups and surrounded by thousands of film stills, began combining images they felt visually belonged together. Individually, they created one or two collections, chosen out of the 500 sets of stills on their tables. Subsequently, they wrote down on post-its the characteristics which they had centred their collection around, and then associated those labels with the categories of ‘colour’, ‘shape’, ‘movement’, ‘texture’ (all particularly relevant to the SEMIA project) or ‘other’. This way, they manually produced the ‘features’ which extraction in the first stage of the project revolves around, but focussing on those that held particular appeal or relevance to them as (potential) users. Oftentimes, participants decided on highly abstract characteristics (often in terms of the emotions images represented or elicited), which ended up being labelled as ‘other’. Among the four pre-determined categories, ‘form’ was the most chosen one.
In the next time slot, the attendees were asked to highlight their preferences among a wide range of interface types. Here, they could choose between tangible interfaces, pointing device interfaces, motion tracking interfaces, text-based interfaces, touch & gesture interfaces, mixed interfaces – AR, mixed interfaces – VR, speech/sound interfaces and toggle user interfaces (or combinations thereof). All groups of participants were particularly attracted to the tangible interface types, which enable users to interact with the information displayed through their physical environment.
For the next series of assignments, seven groups of 3 to 4 people had to put their preferences into practice. Armed with markers, paper and scissors, the groups created their own interfaces on two posters. On a first one, they designed an interface that enabled users to explore a film collection. On a second, they made suggestions as to how an interface might present the results generated in the course of image analysis, on the basis of the users’ explorations. Once again, a number of patterns emerged in the participants’ suggestions. First, all groups designed interfaces that produced unexpected results, or in other words: that embraced serendipity. Second, many of the prototypes proposed were spatial installations. Third, a great many groups saw potential for new ways of exploring film collections in 3D, rather than in 2D set-ups. Finally, almost every prototype involved a control device that somehow linked to the user’s senses and/or emotions.
The last assignment of the workshop had the participants individually choose one ‘input’ poster (i.e., one chosen from those that made proposals for specific principles of exploration) and one ‘output’ poster (that is, chosen from among the second type, focussing on the presentation of exploration results). The most often-selected ‘input’ poster showed an interface that favoured unintended encounters: it had a person entering an immersive experience, where the interface reversed everything he or she did or gave expression to – their movements or emotions, for instance – by displaying films representing or eliciting the opposite or inverse. Within this proposed set-up, users could however ‘take back control’ by using an app on their mobile phones. The most often-chosen ‘output’ poster showed an interface whereby the result of a search was an actual film, rather than a graph (so, the analysis result as translated back into an image selection, rather than the analysis as an abstraction).
The workshop’s outcomes will be taken into consideration during a first creative brainstorm session with the SEMIA partners at the Amsterdam University of Applied Sciences, who will be developing prototypes for an interface that gives users access to the image analysis tool developed by the University of Amsterdam’s Informatics department.
The clip below gives a visual impression of this most inspiring day.
On May 16, 2018 Nanne van Noord defended his PhD thesis on learning visual representations of style at the University of Tilburg. He conducted his PhD research as part of the REVIGO project, prior to joining the SEMIA team. Below, he provides a short summary of his PhD thesis; a digital version of the thesis can be found here. The insights he gained carrying out this research feed into the feature extraction and analysis portion of the SEMIA project.
An artist’s style is reflected in their artworks. This style is independent from the content of the artwork, two artworks depicting two vastly different scenes (e.g., a beach scene and a forest scene) both reflect the artist’s style. By recognising the style of the artist, experts, and sometimes even laymen, can tell the same artist created both artworks. Replicating this ability for connoisseurship in a computer, and potentially even giving a computer the ability to produce artworks in the style of the artist, is the main goal of the work I did for my thesis.
To analyse artworks with a computer we can use techniques from the field of computer vision. Traditionally, these techniques rely on handcrafted features to describe the characteristics of an image. However, in recent years the field of computer vision has been revolutionalised by the emergence of deep learning models. These are models which learn from the data a feature representation optimised for a task.
Deep learning models have been shown to be enormously successful on a wide range of computer vision tasks. Therefore, in my thesis I explore the application of deep learning models for learning representations of the artist’s style. By learning the representation we might discover new visual characteristics of artists, enriching our understanding of the artist’s style. Moreover, such a representation might enable new and novel applications.
One of the ways in which the SEMIA project team has sought from the start to further develop its key concerns and objectives, is through the organization of a number of workshops involving representatives of the three ‘user groups’ the project addresses.
The first workshop, which took place on 7 February 2018, brought together media scholars and heritage professionals, along with a number of artists who, as part of their creative practice, repurpose moving image materials in different ways. The workshop’s objective was twofold: on the one hand, it sought to discuss the current ‘state of the art’ in visual analytics research for (archival) moving images, as well as to share amongst project members and other participants some basic knowledge of the underlying mechanisms for (automated) feature extraction and image analysis. On the other, the workshop sought to establish, through discussions with participants, possibilities and limitations in the use of such methods, specifically for media history research and heritage presentation. Our aim was for those discussions to provide input for the remainder of the SEMIA project, specifically in going forward with feature extraction (the first, but iterative phase of the tool development work).
The programme consisted of a combination of presentations, followed by responses, and two series of discussions with participants (first in smaller groups, then plenary). The choice of presentations was determined on the basis of a prior selection of image features identified as particularly relevant for the project – either because of their alignment with existing research interests, or for more pragmatic reasons (such as, the labour-intensiveness of extraction and analysis in relation to the project’s length). Those features (colour, specific kinds of shape, specific dimensions of movement, texture) and tasks, introduced at the beginning of the workshop, varied in status: from essential to the project to desirable (but to be tackled only if time allowed); or, from aligning with prior research to more experimental. Speakers and their respondents were chosen in function of their different takes on matters of extraction and analysis: some were scholars, some artists, and some had extensive experience of using extraction and analysis methods (e.g. in media history research) while others took a more exploratory or even speculative stance. The purpose of their interventions was to assess whether choices made prior to the event, made sense – of if not, to generate ideas as to how to tweak them.
Project leader Giovanna Fossati opening the workshop
The workshop was productive in different ways. First, the combination of presentations by Nanne van Noord (SEMIA project member) and Matthias Zeppelzauer (former collaborator of the Vienna Digital Formalism project), benefitted our understanding of the principles behind, and history of, visual analytics, and the differences between working with purpose-designed, task-specific algorithms (feature engineering) and deep-learning techniques. Zeppelzauer’s contribution also provided more insight into computer vision thinking about visual features, and how such features can best be conceptualised – also for the purpose of determining tasks in the retraining of existing networks for deep-learning. (A post elaborating on these definitions and distinctions, and their relevance to SEMIA, will follow in due course.) Second, the presentation by Adelheid Heftberger (likewise, of the completed Vienna Digital Formalism project) prompted us to consider the importance of consensus among project members about the vocabulary they use in communicating about project objectives and procedures – an advice that has since proven very helpful. Third, the presentations by Barbara Flückiger and Gaudenz Halter (of the Film Colors: Technologies, Cultures, Institutions project at the University of Zürich), Frank Kessler and Danai Kleida (involved in a small-scale film movement annotation project at Utrecht University, in collaboration with the Media Ecology Project at Dartmouth College) and once again, project member Nanne van Noord, brought us up to date on recent initiatives in (manual and/or automatic) feature extraction and analysis, as part of ongoing media, resp. art history projects with related concerns. And finally, the presentation by media artist Geert Mul above all proved inspirational in terms of the sort of revelations visual analysis techniques can engender, and taught us that it might make sense to toggle in the project between conceptually separating out the features that extraction and analysis centre on, and considering them in their mutual relations.
The group discussions later on in the day, focusing on one or more features each, further confirmed this. Aside from revealing a great deal about the working habits and research interests of participants, they also taught us about differences in understanding of the nature of, and relations between, image features. Most importantly, they gave us a better idea of what potential users, specifically researchers, are after, in gaining access to digitized collections. Most crucially, such users want to be taken to places (objects, analogies, patterns) they hadn’t tought of before – even if this means that the relations established in the process cannot necessarily be pinpointed exactly, or explained with recourse to empirical evidence. This strengthened us in our assumption that there is indeed a need for more exploratory ways of navigating through collections, if only just as a trigger for more traditional form of search later on.
In the SEMIA project, we investigate the affordances of visual analysis and data visualization for exploring large collections of digitized moving images. In doing so, we try to accomplish a number shifts in relation to other Digital Humanities projects of the past few years that use similar technologies. As we mention in the project description on our About page, our efforts to develop, and repurpose, concepts and tools address a wider audience than just scholars: we also target artists, and users in the creative industries. But there’s other ways in which SEMIA differs from such image analysis and visualization projects, both past and on-going. Below, we list some of the most crucial ones.
First, SEMIA is distinctive in its overallobjectives. The project seeks to develop concepts and tools, not in order to meet very specific film or media studies requirements, but rather to enable users to intuitively explore visual connections between database objects. In the past, and today still, image analysis was often applied – and the tools for it developed – with an eye to answering specific research questions. (For instance, in the context of digital film history, questions about developments in film style. Within our European network, such questions have been leading, among others, in the Vienna Digital Formalism project, now-completed, and the Zürich Film Colors: Technologies, Cultures, Institutions project, still on-going.) While there is certainly a kinship between SEMIA and projects that take such an approach, and while we build on results obtained in the process, we simultaneously try to move on from them. Ultimately, the explorations we seek to enable may lead to concrete research questions; however, we always act in the assumption that the users’ explorations will serve to trigger, rather than to answer those (compare e.g. Masson 2017, 33-34). Therefore, we also do not seek to generate tools for the analysis of specific bodies of work, but rather more robust ones, that allow users to navigate within large corpora of (visually) extremely diverse materials.
(Human-made) selection of images and image series with visually similar features
Second, SEMIA does not make use of semantic descriptors in the same way, or to the same extent, as other projects do. In developing concepts and tools, we don’t rely as much, either on metadata ingested with the archival objects themselves (e.g. as catalogue entries) or on the sorts of manually produced annotations that are key to other projects involving image analysis. On the one hand, because we see this project as an effort to find out how collections can be explored, precisely, in the absence of metadata – archival assets that are both scarce, and very time-consuming to produce. In other words, we actually hope that SEMIA will generate ideas on how users can circumvent the general problem of scarcity of metadata in navigating archival collections. On the other hand, and as implied above, we do so because we want to be able to explore collections in other ways than have been tried so far, and on the basis of other connections between discrete items than those that underpin the sorts of search activities that we commonly perform in navigating them. Connections, indeed, that inevitably involve some form of interpretation of the discrete objects, and that are heavily inflected by the dominance in metadating of either classic filmographic or technical information (often added manually or through crowd-sourcing), or identifications of semantic (often object) categories (increasingly done automatically).
A third shift our project seeks to accomplish is to rely more radically on deep-learning techniques – and so-called ‘neural networks’ – as opposed to feature engineering. We intend to release another post on this topic soon, but in essence, this means that the SEMIA Informatics team will not design task-specific algorithms in order to extract pre-defined features from the images in our database (whether image sections, single images, or strings of images/fragments) and subsequently compare them, but rather tweak, and repurpose, networks that have been trained with techniques for automatic feature-learning (that is, the learning of data representations). (The aforementioned repurposing – and retraining – is necessary, because the networks we can rely on were built for different tasks, and different corpora, than we intend to use them for. Once again, we shall elaborate on this in a future post.) Overall, this means that in developing tools for analysis also, we rely to a lesser extent on human intervention. But we do not seek to avoid such human intervention altogether – if only because we need to be able to minimally understand and evaluate the sorts of similarities the system relies on in making connections between discrete objects. Moreover, as it is our aim to support users in their (unique, or at the very least individual) explorations of collections, we would like our tools to adapt to their specific needs and behaviours. Here, human intervention in the form of man-machine interaction will still be desirable.
Finally, SEMIA also explores new principles for data visualization (but ‘new’, in this context, in relation to such practices in the Digital Humanities more broadly – rather than image analysis specifically). Considering the abovementioned goal of enabling users to freely explore collections and make serendipitous connections between objects – yet potentially as a first step toward asking highly precise research questions – the representation of the data we extract in the analysis process need not directly serve an evidentiary purpose. (For more on this topic, see Christian Olesen’s blog post on Moving Image Data Visualization.) This means in turn that we can take inspiration also from artistic projects in image data visualization – an area of practice that is currently gaining a lot of traction. At the same time, users will need to be able to assess what it is they see, if only to be able to determine what they can or cannot use it for (for instance, in the context of their scholarly research). As this is a key area of attention for SEMIA, we will be sure to reflect on it further in later posts, as our team discussions on the topic evolve.
– Eef Masson
References
Masson, Eef. 2017. “Humanistic Data Research: An Encounter between Academic Traditions”. In The Datafied Society: Studying Culture through Data, ed. Mirko Tobias Schäfer and Karin van Es, 25-37. Amsterdam: Amsterdam University Press.